데이터베이스/Elasticsearch

elasticsearch routing 사용하기
[기본구조] elasticserch에서 데이터는 index에 저장되고 index는 shard로 구성되어 있다. 기본적으로 데이터가 shard에 들어가는 기준은 document에 _id를 기준으로 들어가게 된다. 그렇기 때문에 index에 데이터를 조회할 때 어떤 샤드에 값이 저장되어 있는지 알수 없기 때문에 모든 shard에 값을 질의하고 그 값을 조합해서 값을 내려준다. 한번 일반적인 index를 만들고 조회해보자. 아래처럼 Index를 생성하고 "name"에 wedul을 넣고 조회해보겠다. PUT localhost:19200/before-route { "settings": { "number_of_shards": 4, "number_of_replicas": 0 }, "mappings": { "prope..

shard reroute api 테스트
elasticsearch에서는 들어온 요청에 대해서 primary shard, replica shard를 병렬로 요청을하기 때문에 replica가 있는게 좋긴하다. 하지만 replica shard나 primary shard가 제대로 노드에 분배되어 있지 않으면 조회가 특정노드에 몰리거나 인덱싱 시 노드에 부하가 심해질 수 있다. 분배를 위해서는 기본적으로 es cluster에 아래 옵션들이 제공된다. (링크) cluster.routing.allocation.balance.shard - 노드에 샤드를 균등하게 분배 (기본값 0.45f, 값이 높아질수록 노드들에 샤드들이 골고루 분배됨) cluster.routing.allocation.balance.index - 인덱스당 샤드 분배를 균등하게 (기본값은 0...

elasticsearch cluster 구성 시 기본으로 생성되는 index확인
elasticsearch cluster를 사용하기 위해서 cluster를 구성하기전에 꼭 추가해야하는 부분이 있는데 기본으로 생성되는 index에 대한 disable처리가 필요하다. geoip_databases 인덱스 기본적으로 cluster 구성 시 geoip_databases가 인덱스가 추가가 되어있는데 이게 hidden index여서 모르고 지나칠 수 있다. 만약 모르고 클러스터를 구성하고 노드를 조작할 경우 해당 인덱스의 primary shard가 unassigned되면서 cluster 상태가 red가 될 수 있다. 그럼 왜 geoip_databases가 기본적으로 생기는가? 생기지 않도록 할 수 없는가? 해당 인덱스가 생성되는 이유는 ingest.geoip.downloader.enabled 속성..
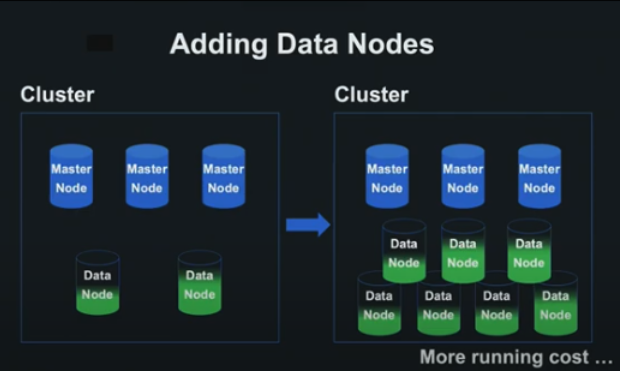
Line 세미나. 대규모 음악 데이터 검색 기능을 위한 Elasticsearch 구성 및 속도 개선 방법 - 2. 클러스터 튜닝
문제상황 - cms 이외에도 외부에 api server를 열어서 데이터를 저장할 수 있도록 열어줬는데 데이터 부하가 되면서 elasticsearch에 부하가 오고 data node가 100프로 되는 등 문제가 발생된다. - 처음에는 쿼리 튜닝등의 방식으로 문제를 해결하였으나 data node의 cpu가 100프로가 되는등의 문제가 계속 유지되었다. - 데이터 노드를 늘림으로서 검색을 여러 서버로 분산하기 때문에 검색 속도를 늘릴 수 있었다. 하지만 비용이 너무 많이 들었다. - 어느 회사든지 간에 끊임 없는 수평확장은 어렵다. 해결방안 - shard와 replica를 구성하여 부하를 여러 노드로 분산하고 가용성을 늘림 - shard와 replica는 일반적인 규칙이 없다. - 상황에 따라 어떤 shard..
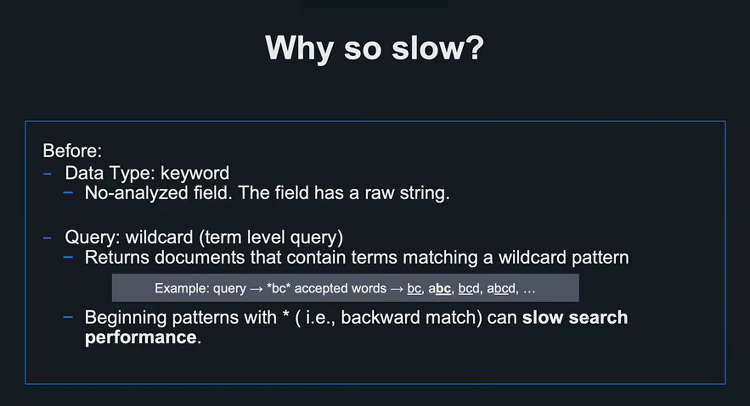
Line 세미나. 대규모 음악 데이터 검색 기능을 위한 Elasticsearch 구성 및 속도 개선 방법 - 1. 검색 쿼리 개선
- 발표자 : Taku Tada 시스템 상황 - 유저가 곡을 검색 할 시 meta search api server에 요청이 들어오고 Elasticsearch에 검색을 요청한다. - 8천 500만건의 데이터가 엘라스틱 서치에 들어가 있다. - 지금 발표하는 내용은 음악에 대한 검색과 책 데이터등에서 활용될 수 있다고 생각한다. - 기존에 검색에 사용되던 플드는 오직 Track Name 하나 뿐이었는데 추후 기능 피처로 트랙이름, 부가적인 트랙정보, 앨범이름, 아티스트 이름, 레이블 프로덕트 코드, ISRC와 같응ㄴ 데이터를 조회 조건으로 같이 걸어야했다. 이로인해 기존에 1초 걸리던 검색이 5초 정도의 시간으로 증가하게 되었다. 느렸던 이유 - 기존에는 keyword 타입으로 와일드 카드를 이용해서 조회를..
Java Lowlevel client bulk api에서 filter_path 사용하기
https://wedul.site/690 Bulk Index 진행 시 search api 느려지는 현상 해결 방법 리서치 현재 회사에서 하고있는 프로젝트에 경우 Elasticsearch를 사용해서 데이터를 제공하고 있다. 서비스 특성상 초당 받는 데이터 업데이트 요청이 많고 real time engine이 아닌 elasticsearch에 거의 리얼타 wedul.site 이전글에서 작성하였듯이 계속해서 쓰기 작업 시 발생할 수 있는 순단을 줄이기 위해서 여러가지 방법을 찾고 있다. 그중 쓰기 작업이 많이 발생할 때 불필요한 response를 줄이기 위해서 filter_path를 적용해보고자 한다. Filter Path rest api 작업 시 필요한 응답값만 받을 수 있는 기능이다. 하지만 Java Hig..
Bulk Index 진행 시 search api 느려지는 현상 해결 방법 리서치
현재 회사에서 하고있는 프로젝트에 경우 Elasticsearch를 사용해서 데이터를 제공하고 있다. 서비스 특성상 초당 받는 데이터 업데이트 요청이 많고 real time engine이 아닌 elasticsearch에 거의 리얼타임 수준의 데이터 변경을 보여줘야한다. 그러다보니 들어오는 요청을 별도의 buffer를 많이 주어 업데이트 할 수 없기 때문에 들어오는 요청을 document id 기준으로 묶어서 bulk 업데이트 될 수있도록 기능을 개발했었다. 회사 블로그에 관련된 내용을 썼었는데 참고 https://techblog.woowahan.com/2718/ 검색을 위한 데이터 다루기 | 우아한형제들 기술블로그 {{item.name}} 안녕하세요. 우아한형제들 검색개발팀 정철입니다. 배달의민족 검색시스..

Nested field에 대한 대체 필드 flattened type
일반적으로 하나의 공통 Document내에 서로 다른 속성을 가지고 있어서 별도의 Document인 것 처럼 저장하고 query하기 위해서 우리는 nested obejct 타입을 많이 사용한다. 사용했었던 예로는 가게 - 메뉴, 상품 - 아이템 정도이다. 하지만 nested 필드의 개수만큼 내부적으로 별도의 도큐먼트로 분리되어 저장이 되고 쿼리 시 상위 도큐먼트와 합쳐져서 보여줘야하는 등에 여러 이유로 nested 필드는 많이 느리다. Elasticsearch nested type설명에도 flattened type을 고려해보라고 써있는거 보면 얼마나 좋지 못한지 사용해보지 않아도 가늠해 볼 수 있다. (실사용에서도 퍼포먼스를 극대화 해도 쉽지 않았다.) 그래서 성능이슈를 해결해보고자 찾던 중 7.3 버전..
Elasticsearch의 Translog 설명
Lucene을 공부하면서 실제 세그먼트를 조작 하고 인덱싱을 반영 하는 부분을 보면서 Lucene에 commit에 대해서 공부했었다. wedul.site/678 Lucene의 commit과 flush의 차이 Lucene에서 데이터 색인을 위해서 사용하는 IndexWriter의 flush와 commit 두 가지 command의 차이를 정리해보자. 두 개의 operation 이름만 보게되면 동일한 동작을 수행할 것 같지만 실질적으로 다른 동작을 wedul.site 그럼 실제로 Elasticsearch에서 이 Lucene commit에 영향을 받는 부분이 어디인지 알아보게 되면서 translog에 대해 공부해봤다. 우선 translog는 양 자체가 워낙 방대하기 때문에 성능을 위해서는 이 부분에 대한 튜닝이 ..
elasticsearch metric 수집 방법
Elasticsearch metric 정보 수집관련해서 요근래 질문을 받았었다. 처음에는 java application이라면 기본적으로 생각하는 JMX metric을 고려했었으나 그때 당시에 이 community를 보고 직접 aggregation해서 influxdb에 수집하는 방법을 선택했던게 생각난다. (실제로 내 입장에서는 jmx로 metric 정보를 보는게 너무 불편했다.) 또 aggregation할 때 spring actuator micrometer를 사용하려 했으나 이곳에서 모으는 데이터를 정제해서 보고자 하는 데이터 형태로 influxdb에 넣는건 좋지 못한 방법이었다. 그래서 결국 pooling방식으로 얻고자 하는 클러스터에 직접 stats관련된 http api를 요청해서 잘 조립해서 inf..