설치

kubernetes 기본 개념정리와 구성 알아보기 (설치 포함)
docker를 사용하면서 그 편리함을 느끼고 있었다. 그리고 요 근래 it회사에서 docker와 kubernets를 이용하여 인프라를 운영을 하는 것을 많이 들었다. 나는 그런 환경을 접해보지는 못했기 때문에 정확하게 kuberntes가 무엇인지 잘 모른다. 그래서 이번 기회에 kubernets(이하 쿠버네티스)에 대한 기본 개념을 정리하고 설치해서 공부를 위한 초석을 닦아보자. 쿠버네티스 (kubernetes) 쿠버네티스는 도커 컨테이너 운영을 자동화 하기위한 오케스트레이션 도구이다. 구글에서 만들었으며 컨테이너를 운영하고 다루기 위한 api와 cli등을 제공한다. 컨테이너 배포 이외에도 효율적인 컨테이너 배치 및 스케일링, 로드밸런싱, 헬스 체크, secure등의 기능을 제공한다. AWS ECS 와 ..

ngrinder Mac os 간단 설치 및 테스트 방법
api의 성능 테스트를 위해서 네이버에서 만든 ngrinder 설치하고 테스트를 진행해봤다. ngrinder는 controller와 agent로 구성이 되어 있는데 이에 대한 내용은 https://naver.github.io/ngrinder/ 해당 내용을 체크하자. 1. Controller 설치 - 톰캣을 설치하고 아래 주소에서 war를 다운받아서 실행시킨다. https://github.com/naver/ngrinder/releases 단, 3.4.2는 테스트 스크립트 실행 시 unexpected token에러가 발생한다. 그래서 3.4.1을 사용하는걸 추천한다. 설치 완료되면 아래 url로 접근 해서 확인 (초기 계정은 admin/admin) - 뒤에 root path는 편의를 위해서 war 파일을 n..

synology ds118에서 redis 설치하기 (패키지 센터가 아닌 직접 설치)
synology에서 docker나 redis 등을 패키지 센터에서 설치하여 사용할 수 있다. 하지만 이상하게 저렴하게 나온 NAS, 그 중에서 x86 cpu를 사용하는 경우에는 패키지 센터에서 직접 redis를 설치할 수가 없다 ㅜㅜ 그래서 방법을 찾았다. 그 방법을 까먹지 않기 위해서 정리해보자. 1. DSM에서 SSH 허용이 부분은 아주 간단하게 DSM > 설정 > 네트워크에서 SSH 허용하여 접속을 킬 수 있다. 보안상 포트는 22가 아닌 다른 번호로 바꾸고 방화벽을 설정하는 것을 추천한다. 자세한건 검색하면 엄청 나오고 간단하다. 2. redis 다운로드redis 설치하여 운용하기 위해서 공식홈페이지에서 다운로드한다. 그리고 SFTP나 FTP 또는 단순하게 DSM에 드래그 해서 파일을 NAS에 옮..

인덱스 생성 및 데이터 삽입
Elasticsearch에서 인덱스를 만들고 타입을 지정하여 데이터를 삽입하는 과정을 정리해보자. elasticsearch는 Restful API가 지원되기 때문에 BSL 쿼리를 이용하여 쉽게 데이터를 조작할 수 있다. 인덱스 생성Methd : put URLI : /{indexname}?pretty 생성된 인덱스 확인 Method : GET URI : _cat/indices?v kibana dev-tool에서 customer 인덱스가 생성된 것을 확인할 수 있다. 타입, Document 생성 및 데이터 추가 Method : PUT URI : /{indexname}/{typename}/[documentid]?pretty 만약 documentid를 넣지 않으면 랜덤으로 만들어서 삽입된다. 입력된 데이터 확인..

Windows Subsystem for Linux (ubuntu)에 Docker 설치
맥에서는 docker 설치와 운용이 쉬웠는데, 맥북이 망가지고 윈도우 컴퓨터를 사용하고 있으니 Docker 사용이 생각보다 쉽지 않았다. 그래서 저번에 Windows Subsystem for linux (ubuntu)를 설치하고 여기에 docker를 올려보면 어떨까 싶어서 도전해 보았다. 우선 docker engine는 WSL에서 실행되지 않아서 호스트 컴퓨터에 Windows용 Docker를 설치해야한다. 그리고 나서 Linux(ubuntu)에서 실행되는 Docker 클라이언트(WSL)가 Windows에 설치된 Docker Engine 데몬으로 명령어를 보내서 운용할 수 있다. 우선 Ubuntu에 Docker를 설치해보자. 1. 우선 패키지를 업데이트 한다.1sudo apt-get updatecs 2. ..
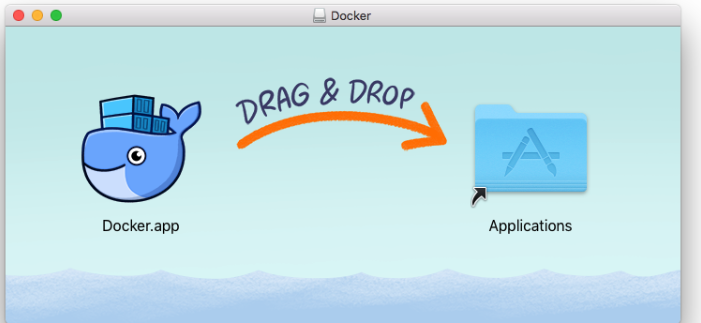
Mac OS에 Docker 설치하기
Mac OS에 Docker 설치는 매우 간단하다. 하단 링크로 들어가서 Docker.dmg파일을 다운받고 설치를 우선 진행한다. Docker 설치링크 DMG파일을 실행하면 다음과 같은 창이 출력되고 드래그 하여 Application으로 옮겨주면 된다. 그 다음 도커를 실행하면 작업표시줄에 출력되고 클릭하면 자세한 상태와 기본 내용이 출력된다. 이제 시작해보자. 도커 시작!

mac환경에서 spring boot에 lombok 설치하기
Lombok 소개 lombok은 모두다 알다시피 getter, setter, construct등 계속해서 추가되어야하는 코드를 어노테이션을 이용하여 자동으로 생성해주는 기능을 제공하는 라이브러리이다. 설치홈페이지에 우선 jar 파일을 다운로드 받는다.https://projectlombok.org/download 다운받은 jar파일을 실행하면 자동으로 ide를 찾아서 설정해준다.설치를 완료하면 다음과 같이 ini에서 설치 여부를 확인할 수 있다.
npm 설치시 ENOSELF 오류 해결 방법
프로젝트 진행을 위해 필요한 라이브러리 설치를 위해 npm 명령어를 사용했는데 다음과 같은 오류가 발생하였다. [명령어] jeongcheol-ui-MacBook-Pro:gridstack jeongcheol$ npm install gridstack --save [에러내용] npm ERR! code ENOSELF npm ERR! Refusing to install package with name "gridstack" under a package npm ERR! also called "gridstack". Did you name your project the same npm ERR! as the dependency you're installing? npm ERR! npm ERR! For more informa..
npm 특정버전 설치하기
NPM을 사용하여 특정 모듈을 설치할 때 다음과 같이한다. npm install webpack 하지만 이럴경우 가장 최신버전이 설치 되기 때문에, 해당 모듈에 dependency를 가지고 있는 다른 모듈에서 에러가 발생될 수 있다. 이를 해결하기 위해서는 그 프로젝트에서 사용하는 특정 버전을 설치해야한다. 특정버전의 모듈을 설치하기 위한 명령어는 다음과 같다. [명령어] 1npm install -g npm@4.6.1cs
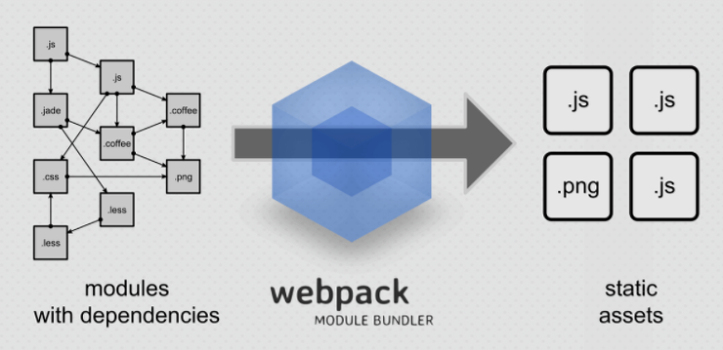
webpack 소개 및 환경 구축
Webpack - webpack은 모듈 번들러이다.- 여러 js 파일을 하나의 번들로 만들 수 있다.- SCSS를 CSS로 돌릴 수 있다.- EM6를 사용할 수 있다.- 스타일로더와 CSS 로더등 다양한 로더를 사용할 수 있다.- 코드 압축을 해주는 UglifyJsPlugin 등 다양한 플러그인등을 사용할 수 있다. 설치방법- node.js를 설치한다. https://nodejs.org/ko/ - npm install -g webpack (npm을 이용하여 webpack을 설치한다)- npm install --save-dev style-loader css-loader (css loader)- npm install --save-dev sass-loader node-sass webpack (scss load..