스프링

spring batch에서 파라미터 시 - 사용 주의
spring batch에서 job param을 전달할 때 관용적으로 -를 붙여서 사용했다. 문제가 된 시점은 프로젝트에서 중복으로 돌면 안되는 배치에 preventrestart를 붙히고 돌리고 있는데 주기적으로 already job param으로 동작한 배치가 있다면서 배치가 자꾸 죽는 이슈가 발생했다. 원인을 파악하기 위해 디버깅을 하던 중 spring batch에서 job의 unique를 판단하는 부분에서 job param으로 전달하고 있는 값들을 job instance에 유니크로 확인하는데 사용을 못하고 있는 부분을 발견했다. 그림을 보면 알겠지만 실제 parameter는 push라는 형태로 전달 되지만 identifying이 false로 되어있는걸 확인할 수 있다. 이러다보니 job instan..

데이터 베이스 버전 컨트롤 Flyway
Spring에서 초기 테이블과 데이터 관리를 위해서 data.sql과 schema.sql을 사용하였다. 하지만 테이블 스키마가 변경되거나 필수로 초기에 들어가야하는 데이터들이 추가되거나 수정되었을 때 히스토리 관리가 잘 되지 않았다. 특히 서로 교류가 잘 되지 않은 경우에서는 컬럼이 추가되거나 무엇이 변경되었는지 알지 못해서 문제를 유발할 수 있기에 이를 관리 할 수 있는 무언가가 필요했다. 그래서 Redgate에서 제공하는 Flyway를 사용해보기로 했다. 우선 내 개인 프로젝트인 timeline에 적용시켜봤다. 데이터베이스 버전관리 Flyway https://flywaydb.org/ 동작 방식 Flyway가 버전관리를 하기위해서 테이블이 생성된다. Flyway가 버전관리는 이 테이블에 데이터베이스의 ..

Spring boot 모니터링 Actuator 소개 및 설치
spring acturator를 통해서 스프링 애플리케이션의 작동여부등을 체크해보자. 설정 우선 gradle 라이브러리를 추가한다. compile 'org.springframework.boot:spring-boot-starter-actuator' 그리고 기존에는 application.properties나 yml에 아래 옵션을 설정해줘야 했지만 기본적으로 설정이 되어있다. endpoints.health.enabled=true 하지만 이는 Spring boot 2.0에서 다음으로 변경되었다. (https://stackoverflow.com/questions/48900892/how-to-enable-all-endpoints-in-actuator-spring-boot-2-0-0-rc1) How to enable..
Spring Reactive Web Application
Sprint 5에서 리액티브 프로그래밍을 지원하는 웹 애플리케이션을 만들 수 있다. 리액티브 프로그램이란? 이전시간에 정리했었지만 스프링 리액티브 프로그래밍을 들어가기 전에 간단하게 정리해 보자. 일반적으로 리액티브 프로그래밍은 비동기, evnet-driven 방식으로 non-blocking 하는 프로그래밍으로써 일반적인 시스템 보다 작은 작은 쓰레드 수가 필요하다. 그럼 왜? 비동기-논블록킹 리액티브 개발이 가능. 기존 멀티쓰레드 블로킹 방식과는 다르게 서버의 응답에 의지하지 않는 효율적 개발이 가능. 서버간에 호출이 잦은 마이크로 서비스에서 사용됨 Spring Web Reactive Module (Servlet 3.1 이상부터 지원) Spring Framework 5는 spring-web-reacti..
Spring reactor Mono와 Flux 정리
지금까지 Spring5에서 추가되었던 리액트 프로그램을 사용하여 간단한 프로그램을 만들어 봤지만 정확하게 Mono와 Flux에 차이와 정의를 정리하지 못한 것 같다. 이번기회에 두 개의 정확한 차이와 사용방법등을 정리해보자. 리액티브 프로그래밍 비동기 블록킹 프로세스로 동작하는 애플리케이션을 논블록킹 프로세스로 동작하기 위해서 지원하는 프로그래밍. (현재 node.js의 동작방식과 유사) 기존 Spring 블록킹 방식 웹에서 서버에 요청이 왔을때 서버는 요청에 대한 적절한 응답을 보내야 하는데 만약 작업이 오래 걸릴 경우에는 요청에 대한 응답이 모두 종료될 때까지 블록킹된다. Spring에서는 그래서 동시 요청 처리를 위해서 멀티 thread를 지원한다. 그러면 하나의 작업이 thread에서 진행되고 다..
[공유] spring에서 생성자 의존성 주입
spring에서 사용하는 의존성 주입에 경우 @Autowired만을 사용하면 나중에 테스트 케이스를 만들때 어려움이 생긴다. 그래서 생성자 주입을 사용하는데 잘 정돈된 사이트가 있어 공유한다. http://multifrontgarden.tistory.com/214
스프링 부트에서 사용하는 JPA 기능 정리
스프링 프레임워크에서 제공하는 JPA는 별도의 구현 클래스 없이 인터페이스만을 사용할 수 있도록 제공한다. 제공되는 인터페이스 JpaRepository는 실행시점에 자동으로 인터페이스 내용을 연결하는 엔티티에 맞게 자동으로 구현해준다. 만약 스프링 JPA 인터페이스에서 제공하지 않는 기능을 사용하고 싶을 때는 메서드명을 특정한 규칙대로 만들어서 사용하면 인터페이스가 알아서 그 이름에 맞는 JPQL을 만들어서 실행해준다. 스프링 JPA 인터페이스는 Mysql같은 RDBMS 뿐만 아니라 Mongodb, Redis와 같은 NoSQL에도 동일한 인터페이스를 사용해서 기능을 사용할 수 있도록 제공해준다. 공통으로 사용할 수 있기에 아주 편리하다. 우선 스프링 부트에 JPA를 사용하기 위해서 Gradle에 라이브러..
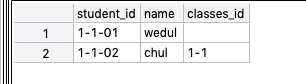
연관관계 매핑 - 다대일 매핑 (단반향)
연관관계 매핑을 해야하는 경우가 많다. 예를 들어 학생을 가지고 학생에 소속 반을 찾거나 반을 사용해서 학생들을 찾거나 할 때가 있다. 이 때 양방향과 단방향 관계가 존재하는데 아래의 객체 형태를 보면 이해가 더 쉽다. 단방향 class Student { Class class; } class Class {} 양방향 class Student { Class class; } class Class { Student student; } 이중에서 먼저 단방향 연관 관계에 대해 먼저 공부해보자. 단방향 연관관계 학생과 반이있다. 학생은 하나의 반에 소속된다. 학생과 반은 다대일 관계이다. (학생이 다, 반이 일) 학생 테이블을 담는 객체는 Student, 반 테이블을 담는 객체는 Classes를 사용한다. 학생 테이..
Spring Boot Cross Domain 처리
웹 브라우저에서 같은 도메인을 사용하는 서비스에 대한 요청은 정상적으로 처리가 되나 도메인이 같지 않은 서비스에 요청을 할경우에 오류가 발생한다. 이는 동일 출처 정책(Same Origin Policy) 라는 정책을 두어 다른 도메인의 서버에 요청하는 것을 보안 문제로 간주하고 이를 차단하는 것 때문에 발생한다. Spring Boot에서 간단한 방식으로 해결할 수 있다. 1. 요청에 @CrossOrigin 애노테이션 붙히기12345@GetMapping("/greet")@CrossOriginpublic Greet greeting() { return new Greet("test");}Colored by Color Scriptercs 2. 특정 도메인에서 오는 요청만 받고 싶을 경우.-> 특정 도메인에서 오는..

스프링 웹플럭스(spring webflux)를 활용한 간단한 리액티브 마이크로 서비스
자바 리액티브 프로그래밍은 리액티브 스트림 명세를 바탕으로 하고 있다. 리액티브 스트림 명세에는 컴포넌트 사이의 비동기 스트림 처리나 이벤트 흐름을 Non Blocking 방식으로 처리하기 위한 문법을 정의한다. 일반적인 옵저버 패턴과 달리 리액티브 스트림에는 시퀀스의 처리, 완료 알림, 실패시 backpressure 적용 등이 추가된다. backpressure는 받는 컴포넌트에서 보내는 컴포넌트에게 얼마만큼의 데이터를 소화할 수 있다고 알려줄 수 있다. 그래서 받는 컴포넌트에서 처리될 준비가 됐을 때만 데이터를 받을 수 있다. 그래서 서로 속도가 다른 컴포넌트 사이의 통신을 할 때 유리하다. 스프링 프레임워크 5 web flux는 Reactor 리액티브 스트림 명세를 기반으로 되어있다. 간단한 Spri..