keyword
Line 세미나. 대규모 음악 데이터 검색 기능을 위한 Elasticsearch 구성 및 속도 개선 방법 - 1. 검색 쿼리 개선
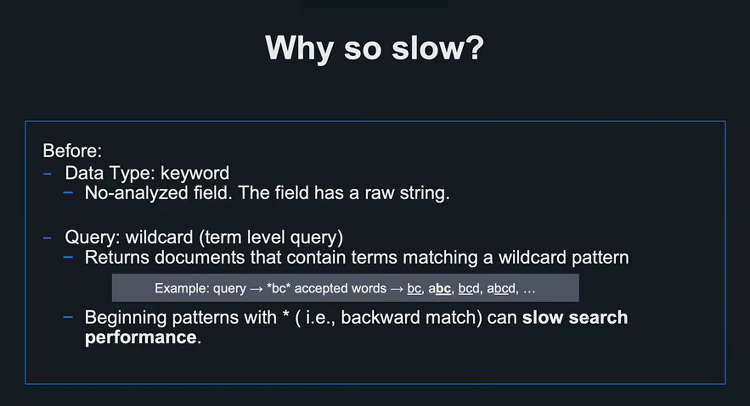
- 발표자 : Taku Tada 시스템 상황 - 유저가 곡을 검색 할 시 meta search api server에 요청이 들어오고 Elasticsearch에 검색을 요청한다. - 8천 500만건의 데이터가 엘라스틱 서치에 들어가 있다. - 지금 발표하는 내용은 음악에 대한 검색과 책 데이터등에서 활용될 수 있다고 생각한다. - 기존에 검색에 사용되던 플드는 오직 Track Name 하나 뿐이었는데 추후 기능 피처로 트랙이름, 부가적인 트랙정보, 앨범이름, 아티스트 이름, 레이블 프로덕트 코드, ISRC와 같응ㄴ 데이터를 조회 조건으로 같이 걸어야했다. 이로인해 기존에 1초 걸리던 검색이 5초 정도의 시간으로 증가하게 되었다. 느렸던 이유 - 기존에는 keyword 타입으로 와일드 카드를 이용해서 조회를..

Nested field에 대한 대체 필드 flattened type
일반적으로 하나의 공통 Document내에 서로 다른 속성을 가지고 있어서 별도의 Document인 것 처럼 저장하고 query하기 위해서 우리는 nested obejct 타입을 많이 사용한다. 사용했었던 예로는 가게 - 메뉴, 상품 - 아이템 정도이다. 하지만 nested 필드의 개수만큼 내부적으로 별도의 도큐먼트로 분리되어 저장이 되고 쿼리 시 상위 도큐먼트와 합쳐져서 보여줘야하는 등에 여러 이유로 nested 필드는 많이 느리다. Elasticsearch nested type설명에도 flattened type을 고려해보라고 써있는거 보면 얼마나 좋지 못한지 사용해보지 않아도 가늠해 볼 수 있다. (실사용에서도 퍼포먼스를 극대화 해도 쉽지 않았다.) 그래서 성능이슈를 해결해보고자 찾던 중 7.3 버전..
엘라스틱 서치 (elasticsearch) fielddata
엘라스틱 서치에서 aggregations를 사용하여 text 필드를 그룹화 하려고 했다. 하지만 이런 오류와 함께 사용이 되질 않았다.12Fielddata is disabled on text fields by default. Set fielddata=true on [your_field_name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory.cs 그래서 엘라스틱 서치 문서를 살펴보던 중 text 필드에 fielddata에 대해 알게 되었다. 대 부분의 필드 들은 기본적으로 자신의 필드가 검색가능하도록 인덱스 처리가 된다. 그러기 위해서..